Check out what's new:
Choosing the right large language model for your use case and budget
Developers across all industries are interested in integrating LLMs into their applications – but how do you determine the right way to do so? In this piece, we share how we compare large language models to understand which is the right fit for our use case.

In 2022, large language models (LLMs) like ChatGPT and GPT-4 went from something that almost no one outside the tech industry talked about to the center of nearly every conversation. All that excitement makes sense. Not only are LLMs a paradigm shifting technology, but the natural language processing market is estimated to reach $91 billion by 2030.
For that reason, developers across all industries are interested in integrating LLMs into their applications – but how do you determine the right way to do so?
In this piece, we’ll share how to compare large language models to help you figure out which is the right fit for your use case. We'll also help you think through whether you should use a general-purpose LLM API like GPT-4 directly or a provider that offers value-added features.
How to compare Large Language Models
Does the LLM you're considering have everything you need?
With the pace of LLM innovation moving at a breakneck speed, rather than evaluate each of the models on the market right now, we decided to provide a glimpse into the rubric we use to compare models.
While the marketing around LLM APIs would have you believe that it’s the parameter count that matters most when it comes to understanding a model’s capabilities, research coming out of the ML community suggests it’s more nuanced.
Here are 8 factors we believe are critical in understanding and comparing different models:
- Compute used for training
- Training data
- Dataset filtering
- Fine tuning process
- Capabilities
- Latency
- Technical requirements
- Price
1. Compute used for training
TL:DR - Certain kinds of training create smaller models that are just as effective
While machine learning experts originally believed that parameter count was what mattered, experiments by DeepMind's Chinchilla project (2022) proved otherwise. Smaller models trained on more data were found to be better or comparable to larger models trained on less data. The LLaMA team took this even further, as explained in a paper published in 2023, with smaller models that were trained on even more data than Chinchilla’s optimal predictions and which were still comparable.
One problem: Compute data isn’t often released by AI companies making it hard to use this to compare models. However, these findings open up opportunities for creating smaller models that are just as effective -- and which could lead to big gains in latency and significant reductions in hardware requirements in the future. They also mean that devs comparing LLMs should be careful not to just choose the one with the largest parameter count.
2. Training data
TL:DR - Niche use cases require fine-tuning or niche models
Whether or not an LLM will be able to respond to a prompt effectively depends greatly on whether its dataset included that information. Most commercial models have been trained on publicly available data like Wikipedia and data scraped from the web.
As a result, most LLMs have a broad but shallow knowledge base. OpenAI's GPT-4 performs better on foreign languages, code, and other niche topics, suggesting that the dataset for GPT-4 was more diverse.
Developers need to make sure that models are able to address their use case – or should consider fine tuning a base model with their own training data. At Inworld, we train our models using data optimized for conversations, games, and immersive experiences. We also dynamically query different LLM APIs based on the conversational context and goals to ensure the highest quality conversation since models vary greatly in their quality for certain kinds of uses.
Models like Meta’s Galactica (trained on scientific papers) or Stanford’s PubMedGPT 2.7B (trained on biomedical literature) present another option for LLMs. Rather than focus on creating general purpose models that know a little about everything, Meta and Stanford trained models that are experts in one area. The proportion of relevant training data also matters. A model whose training data was 90% medical papers will perform better on medical tasks than a much larger model where medical papers only make up 10% of its dataset.
3. Dataset filtering
TL:DR - Data filtering reduces toxicity and bias and optimizes LLMs for specific use cases
As part of the attempt to weed out inaccurate and offensive training data, newer LLMs might lose the capacity to use some of the words older LLMs use – something that may or may not be a good thing depending on your use case. While little is known about the dataset used to train GPT-4, OpenAI has confirmed that they filtered out certain kinds of content, including erotic content, according to a paper published on the project.
LLMs create vocabularies based on how commonly words appear. If more colloquial conversational datasets are removed during data cleaning, newer models might not know how to use common slang. That could work for a corporate use case, but might not be ideal for a character or entertainment-related one.
4. Fine tuning process
TL:DR - Fine tuning is key to model accuracy
Engineers fine tune a LLM to help the model better understand which data in its dataset is likely to be false. Take a model trained on a dataset where some people claim the earth is flat. If 10% claim the earth is flat and 90% claim the earth is round, then the model might say the earth is flat as much as 10% of the time. Fine tuning tells the model that the earth is round 100% of the time.
This is particularly important when it comes to factual information or safety issues. A model that hasn’t been robustly fine tuned might be more likely to repeat offensive things that were said in its training data set and have more difficulties with misinformation. While companies release some information about their fine tuning process, it’s best to test the models yourself using prompts related to your use cases.
5. Capabilities
TL:DR - Some use cases require specific capabilities
While LLMs are increasingly becoming commoditized, they aren’t there yet. Certain models still have unique capabilities. For example, GPT-4 can accept multimodal inputs like video and photos and write up 25,000 words at a time while maintaining context. Similarly, Google’s PaLM is unique because it can generate text, images, code, videos, audio, and more. At Inworld, we orchestrate 30+ models to provide outputs for personality-driven expression through voice, animations, facial expressions, and actions for a more immersive interaction.
6. Latency
TL:DR - Inference latency is higher in models with more parameters
GPT-4’s rumored additional parameters are a key selling point – but there are also drawbacks. Extremely large models can add extra milliseconds between query and response, which significantly impacts real-time applications – especially those with complex architectures.
Smaller models or models that have been compressed have a competitive edge when it comes to inference latency, according to a paper recently published by researchers at Berkeley. While the added benefits of a larger model’s dataset or reasoning capability might lead to slightly higher quality answers, if it slows down your site or application even 100 ms, it could cost you more in the long run. Google found that just half a second of added latency caused traffic to drop by 20%. Similarly, Amazon discovered that every 100 ms delay results in a 1% decrease in revenue. Our own internal tests at Inworld found that GPT-4 was up to 2 times slower than Open AI’s Davinci model.
While OpenAI has bespoke solutions for larger companies who want to train a model to run locally or via their own dedicated server, those are costly. TechTarget estimates the cost of setting up a custom model to be as much as $1 million in hardware alone. Depending on your use case, selecting a model for low latency rather than large parameters might make more sense. At Inworld, we balance capability with latency by dynamically querying different models depending on their evolving real-time latency to ensure the fastest and best responses no matter how much traffic any particular LLM API might be currently experiencing.
7. Technical requirements
TL:DR - Models with more parameters have higher technical requirements
As LLMs grow in size, so do the technical requirements for implementing them in applications. GPT-4’s larger size and complexity would require more compute resources to implement than previous models. That includes more data storage, RAM, and GPUs. For some applications, the additional expense and architectural complexity could be too costly or lead to performance degradation.
8. Price
TL:DR - Newer models cost more and might not provide good price-to-value for every use case
If you think an AI model is too expensive, that will likely change soon enough. In 2022, Open AI announced a number of significant price decreases on its most popular models. However, newer models like GPT-4 are currently much more expensive than other LLMs. Yet, only certain use cases are optimized to take advantage of the improvements it offers over more cost efficient models. Price-to-value, therefore, should be a key consideration when choosing which API to use.
Alternatives to GPT-4 and other LLM APIs

Is a LLM API the only choice when it comes to integrating LLMs?
When evaluating LLM APIs, developers should also consider providers that offer value-added services like prompt generation, automation, additional features, or orchestration.
That’s the future of generative AI according to a piece penned by three partners at the venture capital firm Andreessen Horowitz. “In prior technology cycles, the conventional wisdom was that to build a large independent company, you must own the end-customer,” they write. “It’s tempting to believe that the biggest companies in generative AI will also be end-user applications. So far, it’s not clear that’s the case.”
The piece, instead, suggests that the best way to tap into the end-user market for LLMs is through secondary providers who can package LLMs’ natural language processing capabilities for specific use cases.
Not an out-of-the-box solution
Many use cases for generative AI can’t be fulfilled by a standalone LLM. They require orchestration of multiple models, specialized features, or additional automation to fulfill their promised function.
That includes use cases like financial forecasting, business process automation, or AI characters for video games. For that reason, a direct integration into Microsoft’s product portfolio with all the additional features it offers to help users maximize the efficacy of GPT-4, for example, is a much more holistic and useful integration than ChatGPT Plus can ever be.
For devs, building directly on top of the API is not always the right approach – unless you have deep ML experience on your team, as well as significant resources.
When a value-added LLM provider might be better
You're often better off choosing a provider that offers LLM capabilities for your specific use case. At Inworld, for example, we create AI characters for personality-driven, immersive experiences. We accomplish that by orchestrating 30+ machine learning models to deliver multimodal human expression including LLMs, text-to-speech (TTS), automatic speech recognition (ASR), emotion engines, memory, machine vision, and more.
The expense of just adding commercial TTS and ASR solutions to an AI character in a video game, corporate mascot, or digital sales agent would double your costs. You'd also need to hire a prompt engineer, machine learning infrastructure specialist, and other ML experts just to orchestrate rich character interactions with low latency.
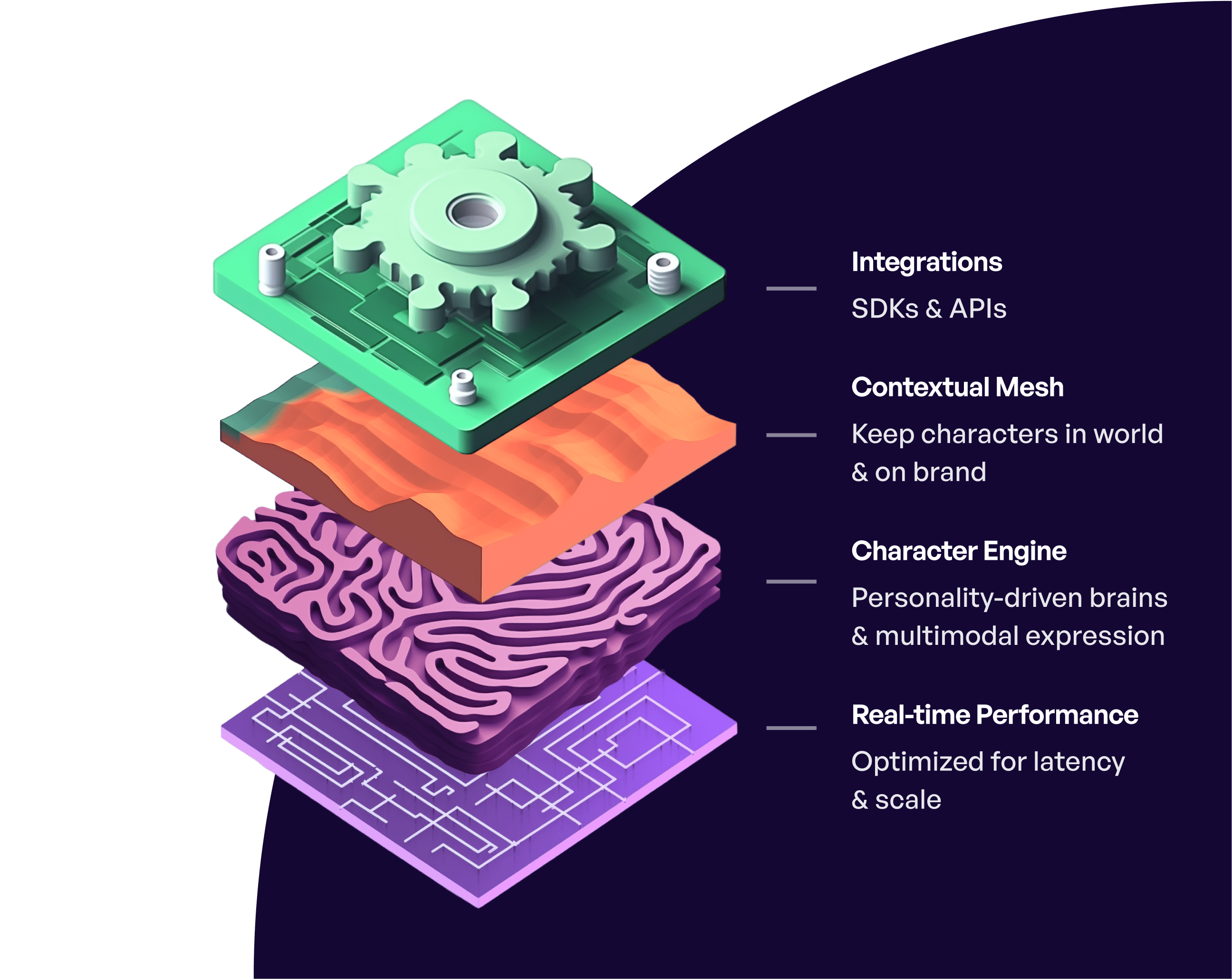
A raw LLM API vs a value-added provider

Compared to an LLM API that just consumes and outputs text, Inworld orchestrates multiple ML models, including our own proprietary models, and adds features that provide significant value – while also reducing development time and costs.
Character Brain
Creative control + multimodality
- Coherent, distinctive personality
- Voices and emotions
- Multi-modal support
- Dynamic memory retrieval from unstructured and streamed sources
- Hybrid mode to support mix of scripted and unscripted elements
- Autonomous goals and actions
Contextual Mesh
Creating a map of context for interactions
- Cross-platform integration
- Advanced narrative controls for world and scene control
- Safety and 4th Wall systems
- Personalization of interactions and narrative
- Multi-character and multi-player/customer orchestration
- Narrative-driven knowledge, goals, and motivations
Real-time Generative AI
Our production-ready real-time GenAI platform
- Real-time latency
- Production-ready scalability and reliability
- Multi-model and provider orchestration
- Managed AI innovation support (auto-update to SOTA)
- Advanced creator-focused feedback and annotation system
- Custom LLMs for distinct use cases through tuning and training
You might think adding these additional capabilities on top of our own LLMs and 3rd party APIs would end up adding significant additional costs. But the ability to focus on specific character-centered use-cases and optimize our technical stack for that, helps us achieve cost optimizations that make it far more cost-efficient to use Inworld than an LLM API.
Conclusion
When it comes to choosing the right LLM for your use case and budget, there are a number of factors to consider. The most critical are things like price, latency, and hardware requirements. Training data, fine tuning processes, capabilities, and vocabulary are also critical in many use cases.
A deep understanding of your use case is key to prioritizing these factors so you can determine which model is right for your application. You also might decide that, after researching all costs, implementing an LLM API directly isn’t the right option. In many cases, working with a company that orchestrates or automates the process for you is best. Paying for additional features, model orchestration, or for optimized latency is often worthwhile so your team can do what it does best – rather than become machine learning engineers overnight.
Read more about the pricing trajectory of LLMs here. Interested in trying out Inworld’s 30+ machine learning models and value-added features? Test out our Studio today for free!